

Machine learning e Autismo. Il 2 Aprile appena trascorso è la giornata mondiale della consapevolezza dell’autismo. Lo scopo è sensibilizzare e incentivare le organizzazioni che si occupano di ricerca sull’autismo di intensificare le collaborazioni per lo studio, diagnosi, trattamento ed integrazione sociale delle persone affette da questi disturbi.
L’information technology sta facendo passi da gigante e in questo articolo parliamo proprio dell’utilizzo del Machine learning e Autismo.
Approfondiamo di seguito la classificazione basata sull’apprendimento automatico del disturbo dello spettro autistico(Machine learning e Autismo) tra i gruppi di età
Premessa
Il disturbo dello spettro autistico (ASD) è una complessa condizione del neurosviluppo che negli ultimi anni ha guadagnato un’attenzione significativa a causa della sua crescente prevalenza e del suo profondo impatto sugli individui, sulle famiglie e sulla società nel suo complesso. In questo studio, esploriamo l’uso di diversi classificatori di apprendimento automatico per il rilevamento accurato dell’ASD nei bambini, negli adolescenti e negli adulti. Inoltre, abbiamo condotto una riduzione delle caratteristiche per identificare le caratteristiche chiave che contribuiscono alla classificazione dell’ASD in ogni gruppo di età utilizzando l’algoritmo di ricerca Cuckoo. La Regressione Logistica ha ottenuto la massima accuratezza rispetto agli altri due modelli.
Parole chiave: Disturbo dello spettro autistico; apprendimento automatico; classificatori; ricerca di cuckoo; Machine learning e Autismo.
- Introduzione
Il disturbo dello spettro autistico (ASD) è un disturbo del neurosviluppo caratterizzato da una serie di anomalie comportamentali e dello sviluppo. Una persona affetta da ASD subisce per tutta la vita effetti sulla sua capacità di interagire e comunicare con gli altri. Poiché i sintomi compaiono spesso nei primi due anni di vita, l’autismo è considerato una “malattia comportamentale” e può essere diagnosticato a qualsiasi età. Gli esperti sostengono che il problema dell’ASD inizia nell’infanzia e si protrae fino all’adolescenza e alla vecchiaia. La malattia ASD ha anche un impatto sul modo in cui il cervello umano si sviluppa. In genere, una persona con ASD non può interagire socialmente o discutere con gli altri.
Gli effetti dell’ASD sulla vita di una persona durano in genere per tutto il resto della sua vita. È importante ricordare che questa malattia può insorgere sia per cause ereditarie che ambientali. I sintomi di questa condizione possono comparire a quasi tre anni di età e possono continuare per il resto della vita. Sebbene un paziente affetto da questa patologia non possa essere totalmente curato, gli effetti possono essere temporaneamente ridotti se i segni vengono colti precocemente. I ricercatori ritengono che l’ASD possa essere legato alla genetica umana, anche se non hanno identificato con precisione i fattori sottostanti.
L’obiettivo principale di questa ricerca è migliorare la diagnosi dell’autismo sviluppando un sistema di apprendimento automatico che utilizzi vari algoritmi di apprendimento automatico per creare un modello predittivo dell’autismo con il massimo livello di accuratezza. La soluzione è fornire un modello predittivo molto accurato in grado di prevedere se un individuo (adolescente, bambino o adulto) è affetto o meno da ASD. L’obiettivo è utilizzare un approccio standard per la diagnosi di autismo e convertirlo in un modello di apprendimento automatico in grado di utilizzare i dati medici per generare previsioni e osservazioni e portare a soluzioni migliori per identificare l’ASD il più precocemente possibile in futuro. - Rassegna della letteratura
Questa sezione presenta alcuni degli studi relativi all’ASD che utilizzano l’apprendimento automatico. Negli studi passati, gli autori hanno utilizzato le domande sullo spettro autistico (AQ) per creare modelli di classificazione dell’ASD. Hanno impiegato il Least Absolute Shrinkage and Selection Operator (LASSO) e il Chi-quadrato per identificare le caratteristiche più rilevanti dal dataset AQ. Successivamente, hanno applicato tre algoritmi di apprendimento automatico supervisionato, Regressione logistica (LR), Random Forest e K-Nearest Neighbors, utilizzando la convalida incrociata K-fold per una valutazione robusta. I risultati hanno indicato che la Regressione logistica ha ottenuto il tasso di accuratezza più elevato, raggiungendo il 97,541%. Questa impressionante performance è stata ottenuta selezionando 13 caratteristiche essenziali basate sul metodo Chi-quadrato.
In un altra ricerca gli studiosi hanno utilizzato la risonanza magnetica funzionale (fMRI) per esaminare come gli individui con autismo e i controlli a sviluppo normale differiscano in termini di influenza causale di un’area cerebrale su un’altra (connettività effettiva) durante i compiti di Teoria della mente (ToM). I partecipanti comprendono 15 persone con autismo ad alto funzionamento e 15 persone a sviluppo normale che fungevano da controllo. Il classificatore SVM ha distinto tra persone con autismo e persone di controllo con sviluppo tipico, con un’accuratezza massima del 95,9%.
I ricercatori hanno studiato il potenziale dell’apprendimento automatico nel differenziare in modo accurato e rapido il disturbo da deficit di attenzione e iperattività (ADHD) e il disturbo dello spettro autistico (ASD) utilizzando i dati della Social Responsiveness Scale. Lo studio utilizza 65 caratteristiche comportamentali con un’accuratezza massima del 96,5%. E’ stato presentato un wrapper di selezione delle caratteristiche che utilizza l’intelligenza di sciame per eseguire la diagnosi di ASD sul repository UCI ML. Lo studio si basa sull’ipotesi che un modello ML possa ottenere un’accuratezza di classificazione superiore con un sottoinsieme minimo di caratteristiche. I risultati supportano questa idea, dimostrando che solo 10 dei 21 tratti essenziali del dataset ASD sono necessari per distinguere i pazienti con ASD da quelli senza. Sorprendentemente, utilizzando questi sottoinsiemi ideali di caratteristiche, la tecnica produce un’accuratezza media compresa tra il 92,12% e il 97,95%.
In un altro studio vengono identificati i primi segni di ASD nei bambini. L’esperimento è stato condotto su dati UCI di bambini utilizzando diversi classificatori e i risultati hanno mostrato che la Regressione logistica ha ottenuto la massima accuratezza tra i modelli, offrendo un approccio promettente per aiutare la diagnosi precoce dell’ASD. I modelli di previsione basati sulle reti neurali convoluzionali (CNN) sono stati applicati ai dati UCI . Dopo aver trattato i dati mancanti e applicato i modelli di apprendimento automatico, i risultati evidenziano la superiorità dei modelli di previsione basati sulle reti neurali convoluzionali (CNN), raggiungendo tassi di accuratezza notevolmente elevati, pari al 98,30%, 96,88% e 99,53%, per lo screening dell’ASD nelle popolazioni di bambini, adolescenti e adulti, rispettivamente. L’apprendimento federale è stato applicato per ottenere un’accuratezza del 98% e dell’81% per i dataset di bambini e adulti con ASD, rispettivamente.
- Metodologia proposta (Machine learning e Autismo)
Il metodo proposto è illustrato nella Figura 1 e comprende la preelaborazione dei dati, la riduzione delle caratteristiche, la valutazione del modello e la previsione dell’ASD. - Figura 1 – Sistema proposto per la previsione dell’autismo –
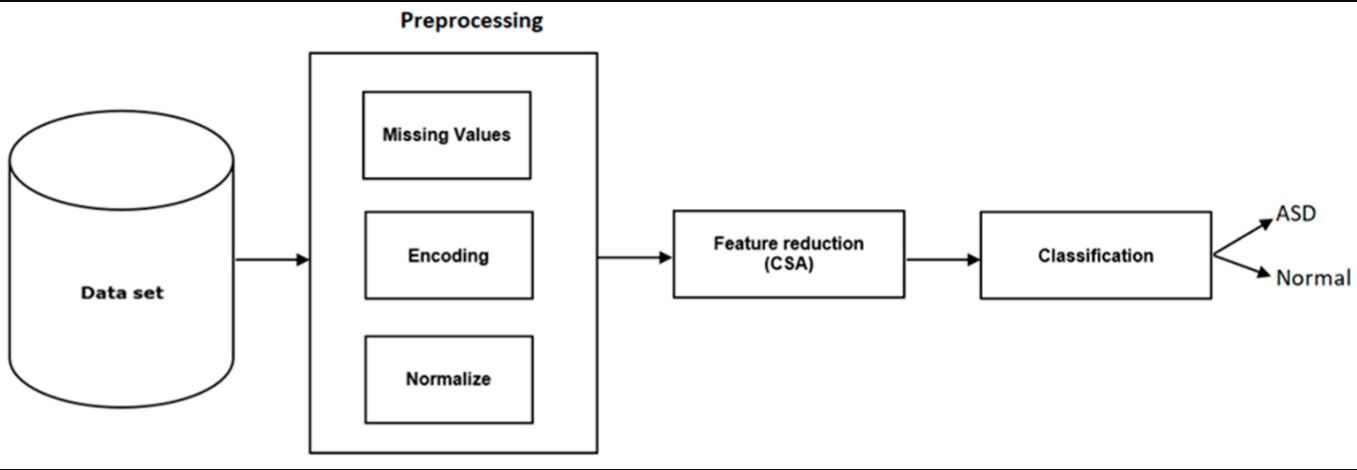
3.1. Preelaborazione (Machine learning e Autismo)
Il data set sull’autismo viene prima preelaborato per rimuovere i valori mancanti e codificare gli attributi categoriali. Il set di dati contiene alcuni valori mancanti nelle singole caratteristiche, in particolare per quanto riguarda il sesso, il Paese, l’etnia e così via, e i diversi tipi di attributi. Per gestire i valori mancanti e gli attributi categorici, il dataset viene sottoposto a una preelaborazione. Per quattro caratteristiche del set di dati viene utilizzata la codifica binaria delle etichette. Ad esempio, il genere attribuito è maschio o femmina. Viene convertito nel valore numerico 0 per una femmina e 1 per un maschio. Il dataset comprende dati raccolti da 89 Paesi. Ogni Paese è rappresentato in ordine alfabetico da 1 a 89, mentre il Paese mancante nel dataset è rappresentato da 90. Il set di dati include un totale di 14 etnie ed è rappresentato da 14 valori utilizzati in ordine alfabetico, mentre il valore mancante è rappresentato come 15. La fase di preelaborazione applicata al set di dati è mostrata nella Tabella 1, mentre i dati prima e dopo la preelaborazione sono mostrati nella Tabella 2.
Tabella 1
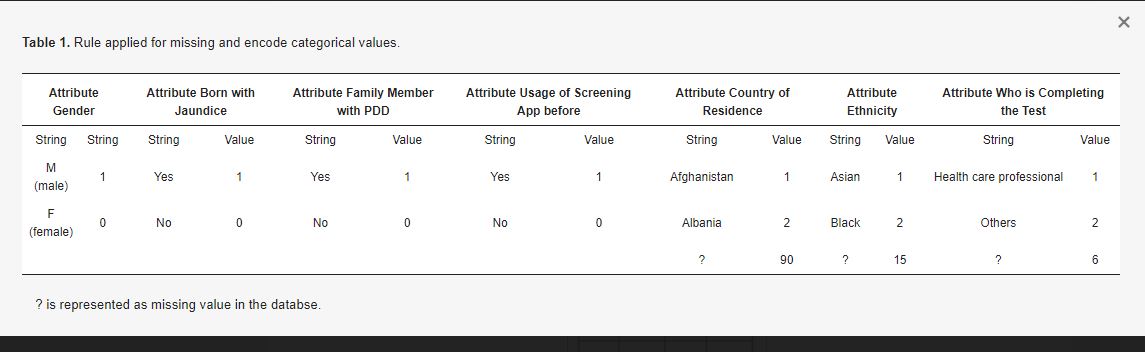
Tabella 1. Regola applicata per i valori mancanti e per la codifica dei valori categorici.
Tabella 2. Dati prima e dopo la preelaborazione.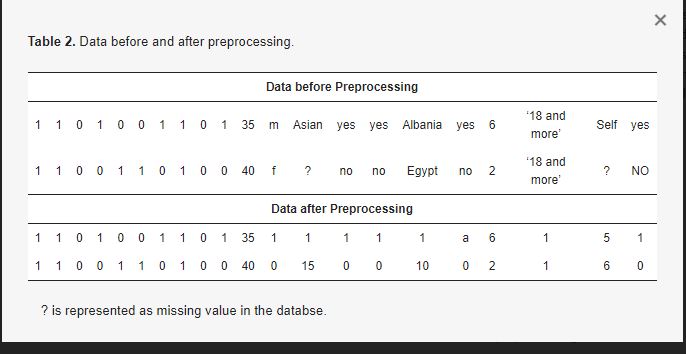
3.2. Algoritmo di ricerca Cuckoo (CSA)
L’algoritmo CSA viene utilizzato per la riduzione delle caratteristiche. L’uso dell’algoritmo di ricerca Cuckoo (CSA) per la selezione delle caratteristiche nel contesto della ricerca sui disturbi dello spettro autistico (ASD) può essere un approccio promettente per migliorare l’accuratezza e l’efficienza dell’analisi dei dati. Di seguito è riportato l’algoritmo per la ricerca a cucù. I parametri utilizzati per la ricerca del cuculo includono popolazione = 20, criterio di arresto = 100, probabilità di abbandonare il nido = 0,25 e fattore di scala per il volo ondulato = 0,6 (Algoritmo 1).
Algoritmo 1 Algoritmo di ricerca a Cuckoo:
- Ottenere in input un set di dati sull’autismo pre-elaborato
- Inizializza una popolazione di soluzioni (nidi)
- Valutare l’idoneità di ciascun nido
- Scegliere un cuculo in modo casuale dal set di dati sull’autismo.
- Generare una nuova soluzione (caratteristiche) modificando la soluzione del cuculo
- Valutare l’idoneità della nuova combinazione di caratteristiche
- Implementare il CSA per cercare sottoinsiemi di caratteristiche ottimali.
- while (criterio di arresto non soddisfatto) Ripetere le fasi successive:
- Generazione di voli Levy: Utilizzare i voli di Levy per generare nuove soluzioni.
- Valutare le nuove soluzioni: Valutare l’idoneità delle nuove soluzioni.
- Sostituire le soluzioni: Sostituire le soluzioni meno idonee con altre migliori.
- Abbandonare le soluzioni: Sostituire occasionalmente alcune soluzioni con nuove soluzioni casuali (esplorazione).
- Valutare l’idoneità dei nidi
- restituire la migliore soluzione trovata
Dopo la riduzione delle caratteristiche, l’etichetta di output (ASD o normale) viene prevista utilizzando diversi metodi di classificazione. L’accuratezza di ciascun classificatore viene valutata e confrontata.
- Risultati sperimentali e discussione
Le prestazioni dell’approccio proposto sono state valutate su set di dati ASD provenienti dal database UCI e implementati in MATLAB.
4.1. Descrizione del set di dati
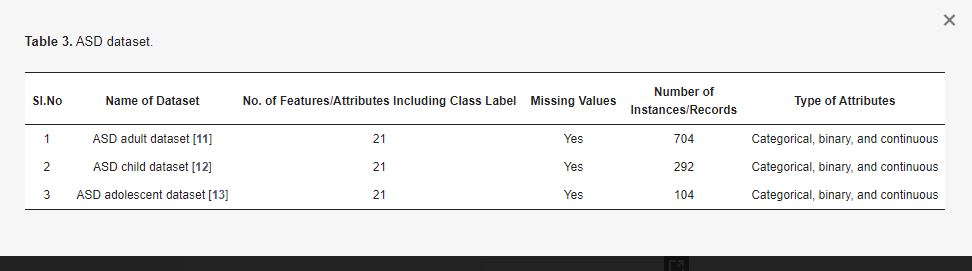
In questa ricerca sono stati utilizzati tre dataset ASD accessibili al pubblico del database UCI, rilevanti per la diagnosi clinica di ASD a varie età. La descrizione del set di dati è riportata nella Tabella 3. Bambini (età compresa tra 4 e 11 anni), adolescenti (età compresa tra 12 e 17 anni) e adulti (età superiore a 18 anni) sono i tre gruppi di età rappresentati nei dataset. Il set di dati comprende un totale di 21 caratteristiche: 10 caratteristiche comportamentali e 10 caratteristiche individuali. Le caratteristiche individuali riguardano le informazioni personali, tra cui età, etnia, sesso, nascita con ittero, Paese, ecc. e le caratteristiche comportamentali riguardano le domande di screening. I dati sono stati raccolti utilizzando un sondaggio in nazioni di tutto il mondo attraverso un’applicazione mobile chiamata ASD Tests.
4.2. Metodi di classificazione (Machine learning e Autismo)
Per la classificazione vengono utilizzati modelli di classificazione come Logistic Regression (LR), K-Nearest Neighbors (KNN) e Support Vector Machine (SVM).
4.2.1. Regressione logistica
È uno degli algoritmi di apprendimento automatico più popolari, utilizzato principalmente per compiti di classificazione binaria. Utilizza una funzione logistica per trovare la curva ottimale da adattare ai punti dati.
4.2.2. K-Nearest Neighbors (KNN)
Questo algoritmo è un metodo di apprendimento automatico semplice e intuitivo, utilizzato sia per la classificazione che per la regressione. Funziona come un approccio non parametrico, basato sull’istanza, che fa previsioni su quanto i punti di dati in un particolare set di dati si assomiglino. L’esperimento è stato condotto su diversi valori di K, e la massima accuratezza è stata ottenuta con K = 10.
4.2.3. Support Vector Machines (SVM)
Le macchine a vettori di supporto (SVM) sono utilizzate principalmente per compiti di classificazione multiclasse e binaria. Il suo obiettivo principale è quello di identificare un confine decisionale ottimale che segmenta efficacemente i punti di dati in classi distinte, massimizzando il margine di separazione tra queste classi.
4.3. Risultati e discussione
Abbiamo applicato tre modelli ML per la valutazione. L’accuratezza è stata calcolata per tutti i modelli utilizzando la seguente equazione:
True Positive(TP)+True Negative (TN)
Accuracy = ______________________________________________________________________________________
True Positive(TP)+False Positive(FP)+True Negative(TN)+False Negative (FN)
(1)
La tabella 4 e la figura 2 mostrano l’accuratezza dei vari modelli ML sui set di dati ASD. Secondo i risultati, rispetto agli altri modelli presenti nel dataset disponibile, la regressione lineare presenta l’accuratezza più elevata. La Tabella 5 fornisce un’analisi comparativa con le ricerche precedenti riguardanti l’ASD.
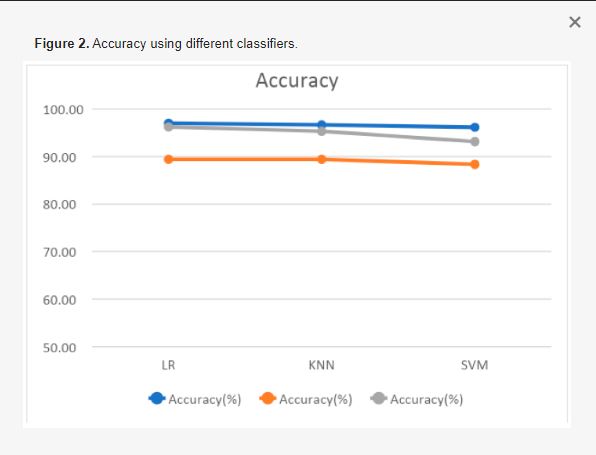

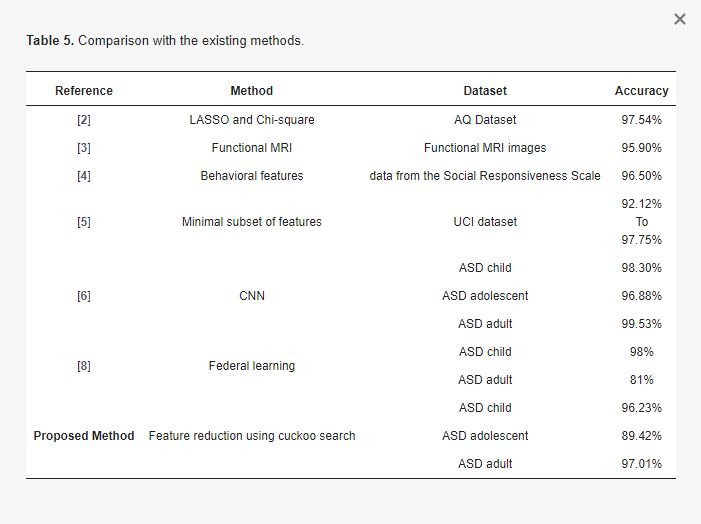
Poiché gli studiosi hanno utilizzato metodi e set di dati diversi, i risultati della Tabella 5 non sono confrontabili. Questa ricerca può essere migliorata con l’utilizzo di tecniche di deep learning, di un maggior numero di set di dati e di caratteristiche. Poiché gli autori di [6] hanno utilizzato la CNN, l’accuratezza raggiunta è molto elevata.
Conclusioni
In questo studio sono stati utilizzati tre set di dati di screening ASD disponibili pubblicamente e offerti dall’archivio di apprendimento automatico dell’UCI per rilevare il disturbo dello spettro autistico (ASD) utilizzando diversi modelli di ML. Questo studio ha valutato diversi modelli di apprendimento automatico per una classificazione accurata e robusta dell’ASD in vari gruppi di età, dalla prima infanzia all’età adulta. I risultati e le intuizioni di questa ricerca contribuiscono a una comprensione più approfondita della diagnosi di ASD, offrendo potenziali vantaggi a clinici, ricercatori e individui nello spettro autistico. Per aumentare la robustezza del sistema e le prestazioni complessive, la ricerca futura dovrebbe concentrarsi su insiemi di dati di grandi dimensioni, migliorando i metodi di selezione delle caratteristiche e utilizzando strategie di apprendimento profondo che combinino CNN e classificazione.
(fonte)
Innovaformazione, scuola informatica specialistica promuove la cultura IT come strumento per aiutare la vita delle persone. L’offerta formativa legata al machine learning, algoritmi e data science copra una serie di corsi rivolti solo alle aziende:
Per altri articoli sul mondo IT potete navigare sul nostro blog QUI.
INFO: info@innovaformazione.net – Tel. 3471012275 (Dario Carrassi)
Vuoi essere ricontattato? Lasciaci il tuo numero telefonico e la tua email, ti richiameremo nelle 24h:
Articoli correlati

Guida TailwindSQL

SAP incassi e riconciliazioni bancarie

Novità di Windows Forms

CancellationToken in .NET

Spieghiamo Graph Neural Networks GNNs
