

Cosa è Kafka e a cosa serve. Casi d’uso di Apache Kafka: Quando usarlo? Quando non usarlo?
Cosa rende Apache Kafka probabilmente lo strumento più comune per lavorare con i dati in streaming? Secondo la Apache Software Foundation, più dell’80% di tutte le aziende Fortune 100 utilizzano Kafka. In questo articolo vengono illustrati gli aspetti e i componenti principali di Kafka, i suoi utilizzi e i migliori scenari per l’implementazione di Kafka.
Cosa è Kafka e a cosa serve?
Apache Kafka è una piattaforma open-source per lo streaming dei dati sviluppata originariamente da LinkedIn. Dopo aver ampliato le capacità di Kafka, LinkedIn l’ha donata ad Apache per un ulteriore sviluppo.
Kafka funziona come una tradizionale coda di messaggi pub-sub, come RabbitMQ, in quanto consente di pubblicare e sottoscrivere flussi di messaggi. Ma si differenzia dalle code di messaggi tradizionali per tre aspetti fondamentali:
- Kafka opera come un moderno sistema distribuito che funziona come un cluster e può scalare per gestire qualsiasi numero di applicazioni.
- Kafka è progettato per servire come sistema di archiviazione e può conservare i dati per tutto il tempo necessario; la maggior parte delle code di messaggi rimuove i messaggi subito dopo che l’utente conferma la ricezione.
- Kafka gestisce l’elaborazione dei flussi, calcolando flussi e insiemi di dati derivati in modo dinamico, anziché limitarsi a passare batch di messaggi.
A cosa serve Kafka (Cosa è Kafka e a cosa serve)?
Kafka è un sistema di elaborazione dei flussi utilizzato per la messaggistica, il monitoraggio delle attività dei siti web, la raccolta e il monitoraggio delle metriche, il logging, l’event sourcing, i registri dei commit e l’analisi in tempo reale. È adatto alle applicazioni di elaborazione dei messaggi su larga scala, poiché è più robusto, affidabile e tollerante agli errori rispetto alle code di messaggi tradizionali.
Kafka open-source o le distribuzioni gestite sono onnipresenti nei moderni ambienti di sviluppo software. Kafka è utilizzato da sviluppatori e ingegneri dei dati di aziende come Uber, Square, Strave, Shopify e Spotify.
Quali sono i concetti fondamentali di Apache Kafka? (Cosa è Kafka e a cosa serve)
Come funziona Kafka? In generale, Kafka accetta flussi di eventi scritti da produttori di dati. Kafka memorizza i record cronologicamente in partizioni tra i broker (server); più broker costituiscono un cluster. Ogni record contiene informazioni su un evento e consiste in una coppia chiave-valore; il timestamp e l’intestazione sono informazioni aggiuntive facoltative. Kafka raggruppa i record in argomenti; i consumatori di dati ottengono i dati sottoscrivendo gli argomenti desiderati. Di seguito lo “schema” di Kafka Cluster.
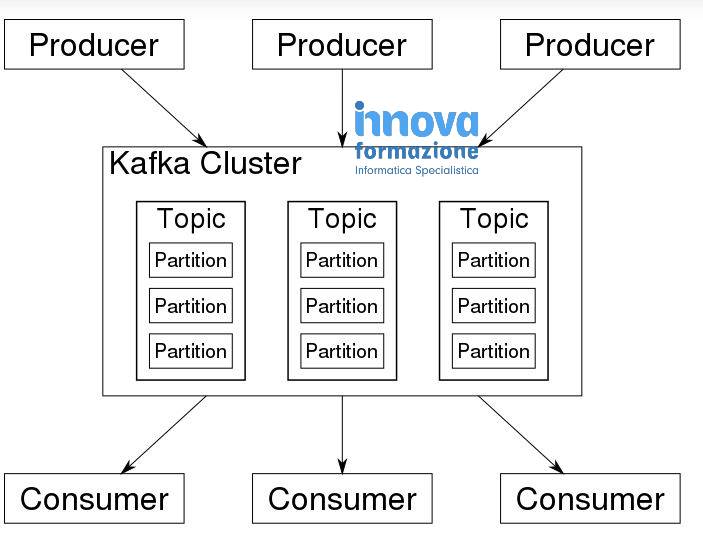
Esaminiamo ciascuno di questi concetti fondamentali in modo più dettagliato.
Eventi (Cosa è Kafka e a cosa serve)
Un evento è un messaggio con dati che descrivono l’evento. Ad esempio, quando un nuovo utente si registra in un sito web, il sistema crea un evento di registrazione, che può includere il nome, l’e-mail, la password, la posizione dell’utente e così via.
Consumatori e produttori (Cosa è Kafka e a cosa serve)
Un produttore è qualsiasi cosa che crea dati. I produttori scrivono costantemente eventi su Kafka. Esempi di produttori sono i server web, altre applicazioni discrete (o componenti di applicazioni), dispositivi IoT, agenti di monitoraggio e così via. Ad esempio:
Il componente del sito web responsabile delle registrazioni degli utenti produce un evento “nuovo utente registrato”.
Un sensore meteo (dispositivo IoT) produce eventi “meteo” ogni ora con informazioni su temperatura, umidità, velocità del vento e così via.
I consumatori sono entità che utilizzano i dati scritti dai produttori. A volte un’entità può essere sia produttrice che consumatore; ciò dipende dall’architettura del sistema. Ad esempio, un data warehouse potrebbe consumare i dati da Kafka, quindi elaborarli e produrre un sottoinsieme preparato per essere reindirizzato tramite Kafka a un’applicazione ML o AI. I database, i data lake e le applicazioni di analisi dei dati agiscono generalmente come consumatori di dati, memorizzando o analizzando i dati che ricevono da Kafka.
Kafka funge da intermediario tra produttori e consumatori.
Broker e cluster (Cosa è Kafka e a cosa serve)
Kafka viene eseguito su cluster, anche se ora esiste una versione serverless di Kafka in anteprima su AWS. Ogni cluster è composto da più server, generalmente chiamati broker (e talvolta chiamati nodi).
Questo è ciò che rende Kafka un sistema distribuito: i dati nel cluster Kafka sono distribuiti tra più broker. E in un cluster Kafka esistono più copie (repliche) degli stessi dati. Questo meccanismo rende Kafka più stabile, tollerante agli errori e affidabile; se si verifica un errore o un guasto in un broker, un altro broker interviene per svolgere le funzioni del componente malfunzionante e le informazioni non vanno perse.
Topics (Cosa è Kafka e a cosa serve)
Un topic di Kafka è un registro immutabile di eventi (sequenze). I produttori pubblicano eventi nei topic di Kafka; i consumatori si iscrivono ai topic per accedere ai dati desiderati. Ogni topic può servire dati a molti consumatori. Continuando con il nostro esempio, il componente di registrazione del sito web pubblica gli eventi “nuovo utente” (tramite Kafka) nel topic “registrazione”. Gli abbonati, come le applicazioni di analisi, le applicazioni di newsfeed, le applicazioni di monitoraggio, i database e così via, consumano a loro volta gli eventi dall’argomento “registrazione” e lo utilizzano insieme ad altri dati come base per la fornitura dei propri prodotti o servizi.
Partizioni
Una partizione è la più piccola unità di memorizzazione in Kafka. Le partizioni servono a dividere i dati tra i broker per accelerare le prestazioni. Ogni argomento di Kafka è diviso in partizioni e ogni partizione può essere collocata su un broker separato.
Ingerire facilmente i dati da Kafka usando SQLake
Se state pensando di utilizzare Apache Kafka, SQLake può rendere molto semplice l’inserimento dei dati in Kafka. Ecco un esempio di come farlo:
Creare la tabella di staging:
CREATE TABLE default_glue_catalog.upsolver_samples.orders_raw_data() PARTITIONED BY $event_date;
Successivamente, è possibile creare un lavoro COPY FROM come segue:
CREATE SYNC JOB “extract data from kafka”
START_FROM = BEGINNING
CONTENT_TYPE = JSON
AS COPY FROM KAFKA upsolver_kafka_samples
TOPIC = ‘orders’
INTO default_glue_catalog.upsolver_samples.orders_raw_data;
COMMENT = ‘Load raw orders data from Kafka topic to a staging table’;
I migliori casi d’uso di Apache Kafka: Per cosa si usa Kafka?
Vediamo i casi d’uso più comuni di Apache Kafka.
Tracciamento delle attività
Questo è stato il caso d’uso originale di Kafka. LinkedIn aveva bisogno di ricostruire la sua pipeline di monitoraggio delle attività degli utenti come un insieme di feed publish-subscribe in tempo reale. Il tracciamento delle attività è spesso ad alto volume, in quanto ogni visualizzazione di pagina dell’utente genera molti messaggi di attività (eventi):
- clic dell’utente
- registrazioni
- Mi piace
- tempo trascorso su determinate pagine
- ordini
- cambiamenti ambientali
Questi eventi possono essere pubblicati (prodotti) su argomenti Kafka dedicati. Ogni feed è disponibile per (consumato da) un numero qualsiasi di casi d’uso, come il caricamento in un data lake o in un magazzino per l’elaborazione offline e la creazione di report.
Altre applicazioni si iscrivono agli argomenti, ricevono i dati e li elaborano secondo le necessità (monitoraggio, analisi, report, newsfeed, personalizzazione e così via).
Esempio di scenario: Una piattaforma di e-commerce online potrebbe utilizzare Kafka per tracciare le attività degli utenti in tempo reale. Ogni attività dell’utente, come le visualizzazioni dei prodotti, le aggiunte al carrello, gli acquisti, le recensioni, le query di ricerca e così via, potrebbe essere pubblicata come evento in argomenti Kafka specifici. Questi eventi possono poi essere scritti in memoria o consumati in tempo reale da vari microservizi per raccomandazioni, offerte personalizzate, reportistica e rilevamento delle frodi.
Elaborazione dei dati in tempo reale
Molti sistemi richiedono l’elaborazione dei dati non appena sono disponibili. Kafka trasmette i dati dai produttori ai consumatori con una latenza molto bassa (5 millisecondi, per esempio). Questo è utile per:
- Organizzazioni finanziarie, per raccogliere ed elaborare pagamenti e transazioni finanziarie in tempo reale, bloccare transazioni fraudolente nell’istante in cui vengono rilevate o aggiornare i cruscotti con prezzi di mercato aggiornati al secondo.
- Manutenzione predittiva (IoT), in cui i modelli analizzano costantemente i flussi di metriche provenienti dalle apparecchiature sul campo e attivano allarmi immediatamente dopo aver rilevato deviazioni che potrebbero indicare un guasto imminente.
- Dispositivi mobili autonomi, che richiedono l’elaborazione dei dati in tempo reale per navigare in un ambiente fisico.
- Aziende del settore logistico e della catena di approvvigionamento, per monitorare e aggiornare le applicazioni di tracciamento, ad esempio per tenere costantemente sotto controllo le navi da carico per le stime di consegna in tempo reale.
Uno scenario esemplificativo: Una banca potrebbe utilizzare Kafka per elaborare le transazioni in tempo reale. Ogni transazione avviata da un cliente potrebbe essere pubblicata come evento in un topic Kafka. Quindi, un’applicazione potrebbe consumare questi eventi, convalidare ed elaborare le transazioni, bloccare quelle sospette e aggiornare i saldi dei clienti in tempo reale.
Messaggistica
Kafka funziona bene come sostituto dei message broker tradizionali; Kafka ha un throughput migliore, partizionamento, replica e fault-tolerance integrati, oltre a migliori attributi di scalabilità.
Scenario di esempio: Un’applicazione di ride-hailing basata su microservizi potrebbe utilizzare Kafka per l’invio di messaggi tra servizi diversi. Ad esempio, quando un utente prenota una corsa, il servizio di prenotazione potrebbe inviare un messaggio al servizio di abbinamento dei conducenti attraverso Kafka. Il servizio di driver-matching potrebbe quindi trovare un autista nelle vicinanze e inviare un messaggio di risposta, il tutto in tempo quasi reale.
Metriche operative/KPI
Kafka viene spesso utilizzato per i dati di monitoraggio operativo. Si tratta di aggregare le statistiche delle applicazioni distribuite per produrre feed centralizzati di dati operativi.
Esempio di scenario: Un fornitore di servizi cloud potrebbe utilizzare Kafka per aggregare e monitorare in tempo reale le metriche operative di vari servizi. Ad esempio, metriche come l’utilizzo della CPU, l’utilizzo della memoria, il conteggio delle richieste, il tasso di errore e così via, provenienti da centinaia di server, potrebbero essere pubblicate su Kafka. Queste metriche possono poi essere utilizzate dalle applicazioni di monitoraggio per la visualizzazione in tempo reale, gli avvisi e il rilevamento delle anomalie.
Aggregazione dei log
Molte organizzazioni utilizzano Kafka per aggregare i log. L’aggregazione dei log comporta in genere la raccolta dei file di log fisici dai server e la loro collocazione in un repository centrale (come un file server o un data lake) per l’elaborazione. Kafka filtra i dettagli dei file e astrae i dati come flusso di messaggi. Ciò consente un’elaborazione a bassa latenza e un supporto più semplice per più fonti di dati e per il consumo di dati distribuiti. Rispetto a sistemi incentrati sui log come Scribe o Flume, Kafka offre prestazioni altrettanto buone, maggiori garanzie di durata grazie alla replica e una latenza end-to-end molto più bassa.
Scenario di esempio: Un’azienda con un grande sistema distribuito potrebbe utilizzare Kafka per l’aggregazione dei log. I log di centinaia o migliaia di server, applicazioni e servizi potrebbero essere pubblicati su Kafka. Questi registri potrebbero essere utilizzati da uno strumento di analisi dei registri o da un sistema di gestione delle informazioni e degli eventi di sicurezza (SIEM) per la risoluzione dei problemi, il monitoraggio della sicurezza e il reporting sulla conformità.
Per ulteriori informazioni su implementazioni specifiche, si consiglia di consultare la pagina dei casi d’uso del progetto Kafka sul sito web della Apache Software Foundation.
Quando non usare Kafka
Data la portata e la scala di Kafka, è facile capire perché lo si possa considerare una sorta di coltellino svizzero delle applicazioni per i big data. Tuttavia, è soggetto ad alcune limitazioni, tra cui la sua complessità generale, e ci sono scenari per i quali non è appropriato.
“Dati “piccoli
Poiché Kafka è stato progettato per gestire grandi volumi di dati, è eccessivo se si ha bisogno di elaborare solo una piccola quantità di messaggi al giorno (fino a qualche migliaio). Utilizzate code di messaggi tradizionali come RabbitMQ per insiemi di dati relativamente piccoli o come coda di attività dedicata.
ETL in streaming
Nonostante Kafka disponga di un’API di flusso, è difficile eseguire trasformazioni di dati al volo. È necessario costruire una pipeline complessa di interazioni tra produttori e consumatori e poi mantenere l’intero sistema. Questo richiede un lavoro e uno sforzo considerevoli e aggiunge complessità. È meglio evitare di usare Kafka come motore di elaborazione per i lavori ETL, soprattutto quando è necessaria l’elaborazione in tempo reale. Detto questo, esistono strumenti di terze parti che funzionano con Kafka per offrire ulteriori e robuste funzionalità, ad esempio per ottimizzare le tabelle per l’analisi in tempo reale.
Riassumendo i casi d’uso di Kafka
La potenza e la flessibilità di Kafka sono i fattori chiave della sua popolarità. È collaudato, scalabile e tollerante agli errori. Kafka è particolarmente utile in scenari che richiedono l’elaborazione dei dati in tempo reale e il monitoraggio delle attività delle applicazioni, oltre che per scopi di monitoraggio. È meno adatto per le trasformazioni dei dati al volo, per l’archiviazione dei dati o quando si ha bisogno solo di una semplice coda di attività. In questi casi si possono utilizzare strumenti che sfruttano Kafka (o altre tecnologie di streaming come Amazon Kinesis).
(fonte)
Innovaformazione, scuola informatica specialistica promuove la cultura e l’ambito Big Data.
In particolare trovate il Corso Apache Kafka che fa parte dell’area Corsi Big Data. Corsi rivolti alle aziende.
INFO: info@innovaformazione.net – tel. 3471012275 (Dario Carrassi)
Vuoi essere ricontattato? Lasciaci il tuo numero telefonico e la tua email, ti richiameremo nelle 24h:
Articoli correlati

EasyJet utilizza AI

Big Data e Calcio

Data Analyst vs Data Scientist

Strumenti per prevedere i prezzi dei voli

A cosa serve Elasticsearch
