Introduzione Uber Michelangelo Machine Learning
Negli ultimi anni, l’adozione e l’impatto del Machine learning (ML) in Uber hanno subito un’accelerazione in tutte le linee di business. Oggi, il ML gioca un ruolo chiave nell’attività di Uber, essendo utilizzato per prendere decisioni critiche per l’azienda come l’ETA, l’abbinamento rider-autista, la classifica dei pasti a domicilio di Eats e il rilevamento delle frodi.
Michelangelo, la piattaforma di ML centralizzata di Uber, è stata determinante nel guidare l’evoluzione del ML di Uber sin dalla sua introduzione nel 2016. Offre una serie di funzionalità complete che coprono il ciclo di vita end-to-end del ML, consentendo ai professionisti del ML di Uber di sviluppare e produrre applicazioni di ML di alta qualità su scala. Attualmente, circa 400 progetti di ML attivi sono gestiti su Michelangelo, con oltre 20.000 lavori di formazione di modelli al mese. Ci sono più di 5K modelli in produzione, che servono 10 milioni di previsioni in tempo reale al secondo al picco.
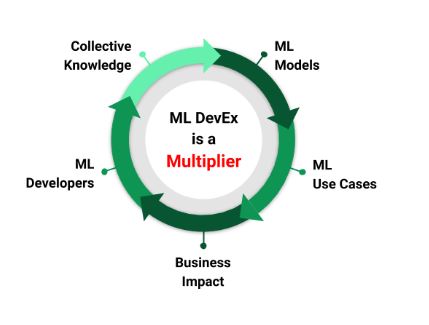
Come illustrato nella Figura 1, l’esperienza degli sviluppatori di ML è un importante moltiplicatore che consente agli sviluppatori di ottenere un impatto aziendale reale. Sfruttando Michelangelo, i casi d’uso del ML di Uber sono passati da semplici modelli ad albero a modelli avanzati di deep learning e, infine, alla più recente IA generativa. In questo blog presentiamo l’evoluzione di Michelangelo negli ultimi otto anni, concentrandoci sul continuo miglioramento dell’esperienza degli sviluppatori ML di Uber.
Il viaggio dell’AI/ML in Uber
Attualmente Uber opera in oltre 10.000 città in più di 70 Paesi, servendo ogni giorno 25 milioni di corse sulla piattaforma e 137 milioni di utenti attivi mensili. Il ML è stato integrato praticamente in ogni aspetto delle operazioni quotidiane di Uber. Praticamente ogni interazione all’interno delle app di Uber coinvolge il ML dietro le quinte. Prendiamo ad esempio l’app per i ciclisti: quando gli utenti cercano di effettuare il login, il ML viene utilizzato per rilevare segnali di frode come possibili acquisizioni di account. All’interno dell’app, in molte giurisdizioni, il ML viene impiegato per suggerire il completamento automatico della destinazione e per classificare i risultati della ricerca. Una volta scelta la destinazione, il ML entra in gioco per una moltitudine di funzioni, tra cui il calcolo dell’ETA, il calcolo del prezzo del viaggio, l’abbinamento guidatore-conducente tenendo conto delle misure di sicurezza e l’instradamento durante il viaggio. Una volta completato il viaggio, il ML aiuta a rilevare le frodi nei pagamenti, a prevenire i chargeback e ad alimentare il chatbot del servizio clienti.
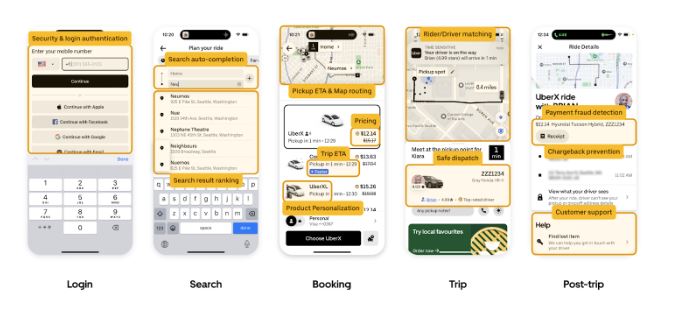
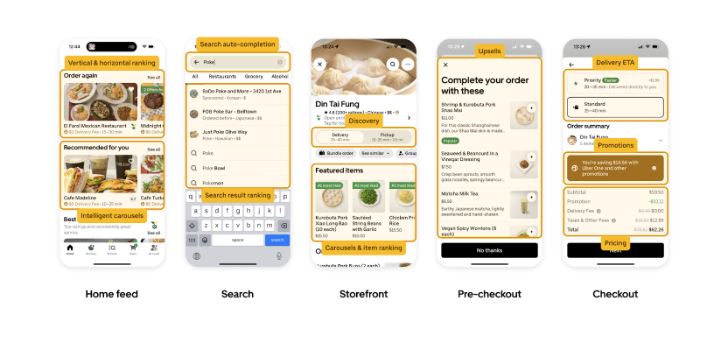
Come si può vedere nella figura sopra, il ML in tempo reale alimenta il flusso degli utenti nell’app per i ciclisti, e lo stesso vale per l’app Eats (e molte altre), come illustrato nella Figura qui sotto.
Riflettendo sull’evoluzione del Uber Michelangelo Machine Learning, si possono distinguere tre fasi:
- 2016 – 2019: durante questa fase iniziale, Uber ha impiegato principalmente l’apprendimento automatico predittivo per i casi di utilizzo di dati tabellari. Algoritmi come XGBoost sono stati utilizzati per compiti critici come la previsione dell’orario di arrivo, la valutazione del rischio e la determinazione dei prezzi. Inoltre, Uber si è addentrata nel regno del deep learning (DL) in aree critiche come la mappatura 3D e la percezione nelle auto a guida autonoma, richiedendo investimenti significativi nella programmazione delle GPU e nelle metodologie di formazione distribuita, come Horovod®.
- 2019 – 2023: La seconda fase ha visto una spinta concertata verso l’adozione della DL e lo sviluppo collaborativo di modelli per progetti di ML ad alto impatto. L’enfasi è stata posta sull’iterazione del modello come codice all’interno di ML monorepo e sul supporto della DL come cittadino di prima classe in Michelangelo. Durante questo periodo, oltre il 60% dei modelli di primo livello ha adottato la DL in produzione e ha incrementato notevolmente le prestazioni del modello.
- A partire dal 2023: La terza fase rappresenta l’ultimo sviluppo della nuova ondata di IA generativa, con l’obiettivo di migliorare l’esperienza degli utenti finali di Uber e la produttività dei dipendenti interni .
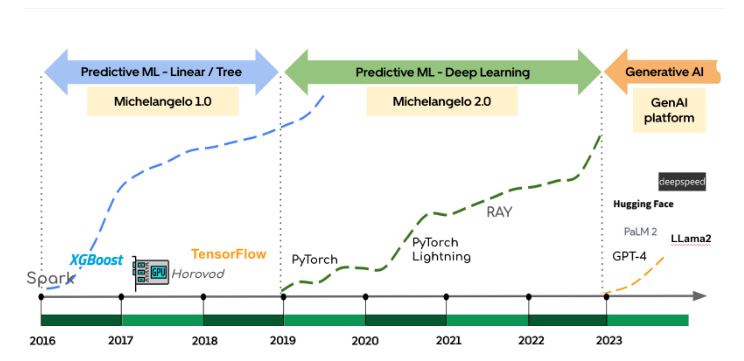
Nel corso di questo percorso di trasformazione, Michelangelo ha svolto un ruolo fondamentale nel far progredire le capacità di ML e nel dare ai team la possibilità di creare applicazioni di ML leader del settore.
Michelangelo 1.0 (2016 – 2019)
Quando Uber ha intrapreso il suo percorso di ML nel 2015, gli scienziati applicati utilizzavano Jupyter Notebooks™ per sviluppare modelli, mentre gli ingegneri costruivano pipeline su misura per distribuire quei modelli in produzione. Non esisteva un sistema per creare pipeline affidabili e riproducibili per la creazione e la gestione di workflow di formazione e predizione su scala, né un modo semplice per archiviare o confrontare i risultati degli esperimenti di formazione. Soprattutto, non esisteva un percorso consolidato per distribuire un modello in produzione senza creare un contenitore di servizio personalizzato.
All’inizio del 2016 è stato lanciato Uber Michelangelo Machine Learning, per standardizzare i flussi di lavoro di ML attraverso un sistema end-to-end che permettesse agli sviluppatori di ML di Uber di costruire e distribuire facilmente modelli di ML su scala. Ha iniziato affrontando le sfide legate all’addestramento scalabile dei modelli e al deployment nei container di produzione (per saperne di più). Poi è stato creato un archivio di funzionalità chiamato Palette per gestire e condividere meglio le pipeline di funzionalità tra i vari team. Il sistema supportava casi d’uso di calcolo delle funzioni sia in batch che in tempo quasi reale. Attualmente, Palette ospita più di 20.000 funzionalità che possono essere sfruttate dai team di Uber per costruire solidi modelli di ML.
Altri componenti chiave di Uber Michelangelo Machine Learning rilasciati sono, ma non solo, i seguenti:
- Galleria: Il registro dei modelli e dei metadati ML di Michelangelo che fornisce un’API di ricerca completa per tutti i tipi di entità ML.
- Manifold: Uno strumento di debugging visuale per il ML di Uber, indipendente dai modelli.
- PyML: Un framework che ha accelerato il ciclo di prototipazione, validazione e produzione di modelli ML in Python.
- Estendere la rappresentazione dei modelli di Michelangelo per ottenere flessibilità su scala.
- Horovod per l’addestramento distribuito.
Michelangelo 2.0 (2019 – 2023)
L’obiettivo iniziale di Michelangelo era quello di avviare e democratizzare il ML in Uber. Entro la fine del 2019, la maggior parte delle linee di business di Uber aveva integrato il ML nei propri prodotti. Successivamente, l’attenzione di Michelangelo ha iniziato a spostarsi da “abilitare il ML ovunque” a “raddoppiare i progetti di ML ad alto impatto”, in modo che gli sviluppatori potessero migliorare le prestazioni e la qualità dei modelli di questi progetti per aumentare il valore aziendale di Uber. Data la complessità e l’importanza di questi progetti, c’era una richiesta di tecniche di ML più avanzate, in particolare di DL, e molti ruoli diversi (ad esempio, data scientist e ingegneri) dovevano spesso collaborare e iterare sui modelli più velocemente, come mostrato nella Figura 5. Ciò ha posto diverse sfide a Michelangelo 1.0, come elencato di seguito.
Panoramica architettonica Uber Michelangelo Machine Learning
Michelangelo 2.0 è incentrato su quattro pilastri. Alla base c’è un’architettura che consente di utilizzare i componenti della piattaforma in modo plug-and-play. Alcuni dei componenti sono costruiti internamente, mentre altri possono essere pezzi di commodity all’avanguardia provenienti da open source o da terze parti. In cima c’è l’esperienza di sviluppo e produzione che si rivolge a scienziati applicati e ingegneri ML. Per migliorare la velocità di sviluppo dei modelli, stiamo semplificando l’esperienza di sviluppo e abilitando le tecnologie per lo sviluppo collaborativo e riutilizzabile. Riteniamo che questo approccio ci consentirà di monitorare e applicare la conformità a livello di piattaforma. Stiamo investendo in esperienze di produzione come il deployment sicuro dei modelli, la riqualificazione automatica dei modelli, ecc. per semplificare la manutenzione e la gestione dei modelli su scala. Infine, ci stiamo concentrando sulla qualità dei modelli e stiamo investendo in strumenti che misurano questa qualità in tutte le fasi e la migliorano sistematicamente.
Ecco alcuni principi di progettazione architettonica per Michelangelo 2.0:
- Definire il tiering dei progetti e concentrarsi sui casi d’uso ad alto impatto per massimizzare l’impatto del ML di Uber. Fornire il self-service ai casi d’uso ML long-tail in modo che possano sfruttare la potenza della piattaforma.
- La maggior parte dei casi d’uso di ML può sfruttare i flussi di lavoro e l’interfaccia utente di Michelangelo, mentre Michelangelo consente anche flussi di lavoro più personalizzati, necessari per casi d’uso avanzati come il deep learning.
- Monolitico vs. plug-and-play. L’architettura supporterà il plug-and-play di diversi componenti, ma la soluzione gestita ne supporterà solo un sottoinsieme per la migliore esperienza utente. Portate i vostri componenti per i casi d’uso avanzati.
- API/code-driven vs. UI-driven. Adottare il principio API first e sfruttare l’interfaccia utente per la visualizzazione e l’iterazione rapida. Supportare l’iterazione del modello come codice per il controllo di versione e le revisioni del codice, comprese le modifiche apportate all’interfaccia utente.
- Decisione di costruire o comprare. Sfruttare le migliori offerte di OSS o Cloud o costruire in casa. Le soluzioni OSS possono essere privilegiate rispetto alle soluzioni proprietarie. Siate cauti riguardo al costo della capacità per le soluzioni Cloud.
- Codificare nella piattaforma le migliori pratiche di ML, come l’implementazione sicura dei modelli, la riqualificazione dei modelli e il monitoraggio delle funzionalità.
Il sistema è composto da tre piani: piano di controllo, piano dati offline e piano dati online. Il piano di controllo definisce le API rivolte all’utente e gestisce il ciclo di vita di tutte le entità del sistema. Il piano dati offline si occupa dell’elaborazione dei big data, come il calcolo delle caratteristiche, l’addestramento e la valutazione dei modelli, l’inferenza batch offline, ecc. Il piano dati online gestisce l’inferenza del modello in tempo reale e il servizio delle caratteristiche, che sono utilizzate da altri microservizi.
Il piano di controllo adotta lo stesso modello di progettazione Kubernetes™ Operator per la modularizzazione e l’estensibilità. Anche le API di Uber Michelangelo Machine Learning seguono le stesse convenzioni delle API di Kubernetes e standardizzano le operazioni sulle entità legate al ML come Project, Pipeline, PipelineRun, Model, Revision, InferenceServer, Deployment, ecc. Sfruttando i macchinari delle API di Kubernetes, tra cui API server, etcd e controller manager, è possibile accedere a tutte le API di Michelangelo in modo coerente, con il risultato di un’esperienza utente più semplice e snella. Inoltre, il pattern API dichiarativo è fondamentale per Michelangelo per supportare la mutazione sia dell’interfaccia utente che del codice in un repository GIT.
Il piano dei dati offline consiste in una serie di pipeline di analisi ML che comprendono l’addestramento, lo scoring, la valutazione e così via, definite come DAG di passi. Le pipeline di ML supportano checkpoint intermedi e resume tra le fasi per evitare la duplicazione delle esecuzioni delle fasi precedenti. Le fasi vengono eseguite su framework come Ray™ o Spark™. Il piano dati online gestisce servizi RPC e lavori di elaborazione in streaming che servono alla predizione online, all’accesso online alle caratteristiche e al calcolo delle caratteristiche quasi in tempo reale.
IA generativa (2023 – oggi)
I recenti progressi nell’IA generativa, in particolare nel campo dei modelli linguistici di grandi dimensioni (LLM), hanno la capacità di trasformare radicalmente le nostre interazioni con le macchine attraverso il linguaggio naturale. Diversi team di Uber stanno studiando attivamente l’uso degli LLM per aumentare la produttività interna con gli assistenti, snellire le operazioni aziendali con l’automazione e migliorare il prodotto finale con un’esperienza utente magica, affrontando al contempo i problemi associati all’uso degli LLM. La Figura sotto mostra il valore potenziale di queste tre categorie di casi d’uso dell’intelligenza artificiale generativa in Uber.
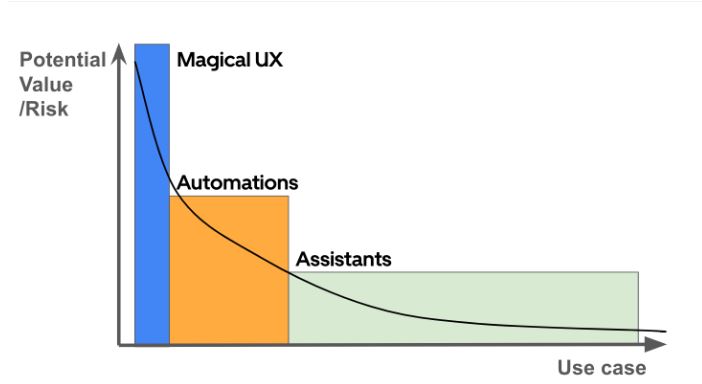
Per sviluppare applicazioni di IA generativa, i team hanno bisogno di accedere a LLM esterni attraverso API di terze parti e/o a LLM open-source ospitati internamente. Questo perché i modelli esterni hanno prestazioni superiori nei compiti che richiedono conoscenze generali e ragionamenti complessi, mentre sfruttando la ricchezza dei dati proprietari possiamo mettere a punto i modelli open-source per ottenere livelli elevati di precisione e prestazioni nei compiti incentrati su Uber, a una frazione del costo e con una latenza inferiore. Questi modelli open-source perfezionati sono ospitati all’interno dell’azienda.
Abbiamo quindi sviluppato Gen AI Gateway per fornire un’interfaccia unificata che consenta ai team di accedere sia ai LLM esterni sia a quelli ospitati internamente, rispettando gli standard di sicurezza e salvaguardando la privacy. Alcune delle funzionalità di Gen AI Gateway includono:
- Registrazione e auditing: Garantire una tracciabilità e una responsabilità complete.
- Guardrail e attribuzione dei costi: Gestione delle spese e attribuzione dell’utilizzo, nonché avviso in caso di utilizzo eccessivo.
- Guardrail di sicurezza e politiche: Garantire che l’utilizzo di LLM sia conforme alle nostre linee guida interne.
- Riduzione delle informazioni personali identificabili (PII): Identificazione e categorizzazione dei dati personali, e loro correzione prima di inviare l’input a LLM esterni.
Per accelerare lo sviluppo di applicazioni di IA generativa in Uber, abbiamo esteso Michelangelo per supportare tutte le funzionalità LLMOps, come la preparazione dei dati per la messa a punto, l’ingegnerizzazione dei prompt, la messa a punto e la valutazione degli LLM, la distribuzione e il servizio degli LLM e il monitoraggio delle prestazioni di produzione. Alcuni dei componenti chiave sono:
- Il Model Catalog presenta una raccolta di LLM precostituiti e pronti all’uso, accessibili tramite API di terze parti (ad esempio, GPT4, Google PaLM) o LLM open-source ospitati internamente su Michelangelo (ad esempio, Llama2). Gli utenti possono esplorare ampie informazioni su questi LLM all’interno del catalogo e avviare vari flussi di lavoro. Ciò include la messa a punto dei modelli in MA Studio o la distribuzione dei modelli in ambienti di servizio online. Il catalogo offre un’ampia selezione di modelli pre-addestrati, aumentando la versatilità della piattaforma.
- LLM Evaluation Framework consente agli utenti di confrontare gli LLM tra diversi approcci (ad esempio, in-house vs. 3P con prompt vs. 3P fine-tuned) e di valutare i miglioramenti con iterazioni di prompt e modelli.
- Prompt Engineering Toolkit consente agli utenti di creare e testare i prompt, convalidare l’output e salvare i modelli di prompt in un repository centralizzato, con un controllo completo delle versioni e un processo di revisione del codice.
Per consentire una messa a punto LLM efficace dal punto di vista dei costi e un servizio LLM a bassa latenza, abbiamo implementato diversi miglioramenti significativi allo stack di formazione e servizio di Uber Michelangelo Machine Learning:
- Integrazione con Hugging Face: Abbiamo implementato un trainer basato su Ray per gli LLM, utilizzando gli LLM open source disponibili su Hugging Face Hub e le librerie associate come PEFT. Gli LLM perfezionati e i metadati associati sono archiviati nel repository dei modelli di Uber, accessibile dall’infrastruttura di inferenza dei modelli.
- Abilitazione del parallelismo dei modelli: Michelangelo in precedenza non supportava il parallelismo dei modelli per l’addestramento dei modelli DL. Questa limitazione limitava la dimensione dei modelli addestrabili alla memoria disponibile della GPU, consentendo, ad esempio, un massimo teorico di 4 miliardi di parametri su una GPU da 16 GB. Nel framework di addestramento LLM aggiornato, abbiamo integrato Deepspeed per abilitare il parallelismo dei modelli. Questa innovazione elimina la limitazione della memoria della GPU e consente di addestrare modelli DL più grandi.
- Gestione elastica delle risorse delle GPU: Abbiamo fornito cluster Ray su GPU con il job controller Michelangelo. Questa soluzione consente l’addestramento di modelli LLM sulle GPU più potenti disponibili in sede. Inoltre, questa integrazione pone le basi per future estensioni che utilizzano le GPU del cloud, migliorando la scalabilità e la flessibilità.
Sfruttando le capacità della piattaforma offerte da Michelangelo, i team di Uber stanno sviluppando con entusiasmo applicazioni basate su LLM. Ci auguriamo di poter condividere presto i nostri progressi nella produzione di LLM.
Conclusione Uber Michelangelo Machine Learning
Il ML si è evoluto in un driver fondamentale per tutte le aree aziendali critiche di Uber. Questo articolo ha raccontato il percorso di trasformazione della piattaforma di ML di Uber, Michelangelo, durato otto anni, sottolineando i miglioramenti significativi apportati all’esperienza degli sviluppatori di ML. Questo viaggio si è svolto in tre fasi distinte: la fase fondamentale di ML predittivo per i dati tabellari dal 2016 al 2019, il passaggio progressivo al deep learning tra il 2019 e il 2023 e la recente avventura nell’IA generativa a partire dal 2023.
Sono stati appresi insegnamenti fondamentali per la costruzione di una piattaforma di ML end-to-end su larga scala a un livello di complessità tale da supportare casi d’uso di ML alla scala di Uber. Gli insegnamenti principali includono:
- L’istituzione di una piattaforma di ML centralizzata, invece di far costruire ai singoli team di prodotto la propria infrastruttura di ML, può migliorare significativamente l’efficienza dello sviluppo di ML in un’azienda di medie o grandi dimensioni. La struttura organizzativa ideale per il ML comprende un team di piattaforma ML centralizzato, integrato da data scientist e ingegneri ML dedicati, inseriti in ogni team di prodotto.
- Fornire flussi di utenti basati sull’interfaccia utente e sul codice/configurazione in modo unificato è fondamentale per offrire un’esperienza di sviluppo di ML senza soluzione di continuità, soprattutto per le grandi organizzazioni in cui le preferenze degli sviluppatori di ML in merito agli strumenti di sviluppo variano ampiamente tra le diverse coorti.
- La strategia di offrire un livello di astrazione di alto livello con modelli di flusso di lavoro e configurazioni predefinite per la maggior parte degli utenti, consentendo al contempo ai power user avanzati di accedere direttamente ai componenti dell’infrastruttura di basso livello per costruire pipeline e modelli personalizzati, si è dimostrata efficace.
- Progettare l’architettura della piattaforma in modo modulare, in modo che ogni componente possa essere costruito con un approccio plug-and-play, che consente la rapida adozione di tecnologie all’avanguardia open source, di fornitori terzi o di sviluppo interno.
- Sebbene il Deep Learning si dimostri potente nel risolvere problemi di ML complessi, la sfida consiste nel supportare infrastrutture DL su larga scala e nel mantenere le prestazioni di questi modelli. Utilizzate il DL solo quando i suoi vantaggi sono in linea con i requisiti specifici. L’esperienza di Uber ha dimostrato che in molti casi XGBoost supera il DL sia in termini di prestazioni che di costi.
- Non tutti i progetti di ML sono uguali. Un chiaro sistema di classificazione del ML può guidare efficacemente l’allocazione delle risorse e del supporto.
La missione di Uber Michelangelo Machine Learning è quella di fornire agli sviluppatori ML di Uber le migliori capacità e strumenti di ML della categoria, in modo che possano costruire, distribuire e iterare rapidamente applicazioni ML di alta qualità su scala. In qualità di team della piattaforma AI, forniamo competenze approfondite in materia di ML, guidiamo la standardizzazione e l’innovazione delle tecnologie ML, creiamo fiducia e collaboriamo con i team dei nostri partner e coltiviamo una cultura ML vivace, in modo che la ML venga abbracciata e sfruttata al massimo delle sue potenzialità. Il nostro impegno in questa missione è incrollabile e siamo incredibilmente entusiasti del promettente futuro che ci attende.
(fonte)
Innovaformazione, scuola informatica specialistica promuove la cultura del machine learning e dell’ AI Generativa. Trovate i relativi corsi rivolti alle aziende sul nostro sito. Corsi sulla AI Generativa e corsi sui Big Data e Machine Learning.
INFO: info@innovaformazione.net – Tel. 3471012275 (Dario Carrassi)
Vuoi essere ricontattato? Lasciaci il tuo numero telefonico e la tua email, ti richiameremo nelle 24h:
Articoli correlati

Arriva Java 25
Cosa è Salesforce Marketing Cloud

Cosa è SAP S/4 HANA e differenze con SAP ECC
Visual Studio 2026

Albania AI diventa Ministro